
I’m sat by the Yonne river in Burgundy, squinting at the sun
in front of me. Specular highlights on the brick next to me; the reflection of
the water tickling the side of the ancient bridge; shade under the trees on the
opposite bank. I’m thinking of brightness and colour relationships between the
various sources, and how knowledge of these can be used if I ever wish to
recreate some of the feeling of the light I’ve seen here today.
In my article Behind the Translation I outlined my view that
we are judging our lighting solely through monitors and EVFs, and that this is
causing us to lose touch with the physical reality of how the light is playing
in the scene. The monitor can be a useful lighting tool, but if we are bound to
it, we are severely limited in our ability to visualise, make proper use of a
recce, pre-light, create lighting lists, achieve consistency, and ultimately,
get what is in our heads onto the screen in a reliable manner. Your incident
meter, your eye and your firm posture in
front of the camera are the tools with which to understand how light is
playing in the physical world.
Today I want to discuss this in a more practical manner by
introducing the way I try to think about exposure and the light in the scene,
and how a thought process like this can lead to valuable conclusions about how
to light and expose.
The diagram below is a conceptual illustration of exposure
in terms of the chain of elements which create the image value for a given pixel,
in the simplified case of matte subjects.
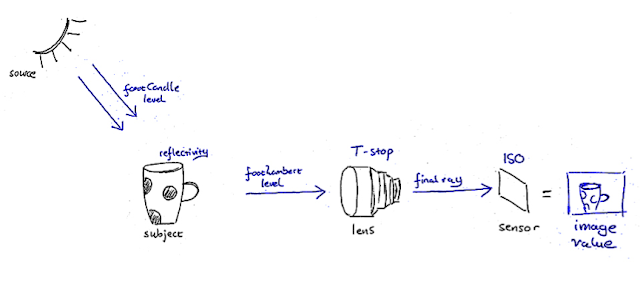
Obviously there’s no single correct way of picturing
something, and this is just my way of breaking it down in my head. But what’s
important is that I have a way, and
every DP must have a clear picture in their head of how the physics of light
and exposure come together to create the backbone of our craft.
Let’s say we have a white mug
with black spots as our subject, as in the diagram. The footcandle level* expresses
the amount of light falling on the subject. Let’s start with the simplified
case that our subject is evenly lit. In this case, the same amount of
footcandles falls on every part of the subject.
The subject has a range of
different reflectivities, the main two being the white of the outside of the
mug and the black of the spots. These two are vastly different in value. The
footlambert level* expresses how bright a certain part of the object looks to
the eye or to the camera, and it is a function of the footcandle level falling
on that part as well as the reflectivity of that part. Although the same
footcandle level falls everywhere on our mug, the white part of it has a much
higher reflectivity and therefore creates a much higher footlambert level than
the black part does, which causes the white part to look brighter than the
black part.
Of course, it may be the case
that there is a more complex light falling on the mug. Let’s say we have
flagged our light source off half of the mug so that the flagged half has a
much lower footcandle level falling on it. Even though the white of the mug has
the same reflectivity everywhere, half of the white has a much higher
footcandle level falling on it, and so generates a much higher footlambert
level. The flagged part of the black spots generates a really tiny footlambert
level, and hence looks very dark.
Sound easy? Okay then, answer
this: we’re in a living room with a nice view into the garden, which is lit by
a scorching hot sun. There’s a black shirt out to dry outside, and our friend
inside is wearing a white shirt. We can all picture from experience that no
matter how dark it is inside, the white shirt inside will still look much
whiter than the black shirt outside. The black shirt, despite being of low
reflectivity, is under such a high footcandle level that it is giving off a
higher footlambert level than the white shirt inside. So how is it possible
that the white shirt still looks brighter than the black shirt?
The answer is that the human
visual system has what we might call spatially adaptive light sensitivity, and
determines the brightness of objects by comparing their footlambert levels to
what’s immediately surrounding them. So the whole of the area visible outside
the window is ‘reduced’ in exposure by our visual system while what’s inside is
amplified. This is what allows us our visual system to have such extraordinary
dynamic range. And, as you might have suspected, cameras don’t do this. If you
expose for the white shirt, and the black shirt outside is indeed emitting more
footlambert, the black shirt will look whiter than the white shirt in our
footage.
So, to summarise what happens
in front of the lens: every part of the scene in front of us is giving off a
footlambert level which determines how bright that part of the scene looks.
That footlambert level is a function of the footcandle level falling on that
part of the scene and the reflectivity of that part of the scene. This is actually
only the case for matte subjects. Glossy and mirror-like subjects and self-illuminating
subjects are a slightly different story, but they still ultimately present a
footlambert level.
So what happens after that? The
footlambert ray representing a given part of the scene passes through the lens
and is affected by the T stop set on that lens before being focused onto the
sensor or film. There is no term in common usage to describe the ray of light
after it has been affected by the T stop, so I coined the term final ray. Understanding this bit is key
to understanding ISO and where to rate cameras, but that’s for another article
- let’s get back to the scene in front of the lens.
Consider that a camera sees
only footlambert levels. It does not know anything about footcandles, and it does not know anything about
reflectivities. It cannot distinguish whether the footlambert level it sees
is coming from a black shirt under bright sunlight or a white shirt in the
shade. Ansel Adams’ zone system, which is well worth studying**, comes out of this
basic truth, and is all about measuring footlambert levels using a spot meter
and using our taste and pre-visualisation skills to decide how bright the part
of the subject that gave rise to that footlambert level should appear in the
final image.
The issue is this: the camera
does not know a black shirt from a white one. A reflective meter – such as a
spot meter – also doesn’t. If you read a footlambert level with a spot meter
and translate the reading directly onto the lens, you’ll get an image in which
the part of the subject which gave rise to the footlambert level you measured
is rendered as middle grey, that is, in the middle of the dynamic range. The
problem is that neither a black shirt nor a white shirt should be middle grey. The
first way to fix this is essentially the zone system: read the footlambert
level, judge how many stops above middle grey the part of the subject you just
measured should be rendered, adjust the reading by that amount (so you’d
overexpose the reading a few stops for a white shirt, and underexpose it a few
stops for a black one) and put the adjusted reading on the lens. Caucasian skin
tone, for example, is typically exposed around one stop over its spot reading.
But there is another method, in
which you don’t have to guess how many stops above or below middle grey you
want a particular object to be rendered: the incident meter. Our incident
meters are actually measuring footcandles – the amount of light falling on a
subject***. That’s why we use an incident meter at the subject. The white dome
on your meter takes an average of the footcandle levels falling on it over a
solid angle of 180degrees. Pointing the dome at the camera gives you a useful
average footcandle reading of the light falling on the front side of your
subject. Reading to the source rather than the camera tells you how many footcandles
are coming from that source.
If we take an incident reading
of a given footcandle level and put the T-stop readout on the lens, we will
expose such that a middle grey reflectivity under that footcandle level is
rendered in the middle of the dynamic range, and all reflectivities above and
below, provided that they are lit by the same footcandle level, will be
rendered above and below in the correct proportion. This way the guesswork is
taken out of it – we don’t need to decide where to place individual
reflectivities, but only what source to pick as our key. Obviously no real
scene is lit by a single equal footcandle level, so we have to decide what
footcandle level to treat as ‘normal’, or in jargon, as key. The key footcandle
level is the footcandle level under which a middle grey reflectance falls in
the middle of the dynamic range, and it is set by reading what you’ve decided
is that level and setting the resulting T stop on the lens.
From here onwards, it’s a
question of personal preference of exposure methods, and as usual, the
important thing is not what your method is, but the fact you have one. I
personally read to the source, not to the camera, and then decide how many
stops above or below key to place that source. I think of a light source being
at, above or below key.
A cloudy sky might be at key
(so I read the light and place that stop on the lens) whereas sunlight be one
to two stops above key (so I read directly to the sun and overexpose the
reading by one to two stops). How do I decide where to place a given source?
The sun needs to feel bright so needs to be above key – that’s an easy one. But
how about a scene consisting of two areas lit by two different sources of
different brightness? How about a wide shot of a subject at a table lit by a
lamp with darkness all around? We’ll see later that the most important thing is
actually the difference between
readings of various sources. It depends on your taste and judgement. This is
the art of exposure, and it’s inextricably bound with the art of lighting. What
do we want to draw attention to, what do we want to keep in the shade, where do
we want to direct the eye? What feeling do we want to evoke? What do we want it to look like? These
are the important questions, and everything we’ve said above is only useful
insofar as it helps us get what is in our heads consistently onto the
screen.
I’m going to present a few
frames from my own work as specific examples of interesting situations in terms
of how to read the light and set an exposure. All images are copyright of their
respective owners - the first two are from TryLife: Jacob's Story and the third from Tea for Two.

Apart from the funny anecdote
that I used a mirror to reflect in the light from a unit outside which we
didn’t have a high enough stand for, this is an interesting shot in terms of
exposure because nothing is at key. The shafts of light on his eye and on the
bed are over two stops above key, and anything on the face which isn’t hit by
those shafts is below key. Let’s review what I mean by that: reading those
shafts to the source reveals a number that is more than two stops closed from
the shooting stop, and reading any part of the face not hit by those shafts
reveals a number that is further open than the lens is. How would I actually
decide on the stop? What actually happened on the day is that this was the last
shot in the scene, and my shooting stop was established earlier in the scene,
on a shot roughly like this:

I metered and lit this with the
idea that there should be bright light coming from the window but that the room
should still be dark. At the character’s face position, the window reading
should be a couple of stops over, and the reading away from the window should
be severely under. So the process might be:
(1) Set
lights outside window and position of blinds to visual taste
(2) Read
to window at face position
(3) Set
shooting stop to be 1-2 stops closed from this reading
(4) Read
away from window and adjust fill or negative fill until this reading is
sufficiently under the shooting stop
Although in practice, it’s
likely that once I had the shooting stop, I set the fill (negative, in this
case) by eye and just quickly checked that the reading was far enough under
key.
Having established a shooting
stop for the scene, when I came to the close-up of the character lying down in
bed, I maintained that stop and it was a matter of controlling the brightness
of those beams to make them look right for the shooting stop, and I did that by
eye. I’m quite comfortable doing things like that by eye, and using the
security blanket of the monitor to make sure I’m not blowing anything. On film,
a spot meter would come out quickly to make sure those beams were in range. On
digital, it’s very easy to use a monitor or waveform to check we’re not
clipping. And using a monitor in that way is not a problem – it’s using it to
its strengths.
Once we have this contact with
the reality of the light in the scene, we can use the monitor to it’s strengths
and still be confident that we understand what’s happening with the light in
the scene. We know what’s going on, we know that it’s unimportant exactly where
the beams fall exposure wise, as long as they’re bright and as long as they
don’t clip. So you use your eye and your taste, and you check the monitor for
clipping.

This is another example of nothing
really at key. The front of our character’s face is under key, and if we were
to read to her ‘kicker’, the light that’s falling on her left ear and shoulder,
the reading would be slightly above key. And pretty much everything behind her
reads above that. To light and expose this, you’d start with the controlling
idea that her face should be below key and that the background should be quite
a lot brighter than that, decide shooting stop using a reading of your choice –
eg ‘her face should be 1.5 below key’ and then check other readings against
your shooting stop and tweak lights to get those readings where you want them.
In the case of this specific shot it would actually be easier to tweak the face
lighting, but whatever you’re tweaking, it should be apparent by now that what
really matters is the contrast – the
difference in reading between the various elements. It’s pretty easy to print
up or down a little in the grade. It’s much harder to make changes to scene
contrast in a pleasing way, and pretty much impossible in most cases to isolate
the effect of a specific source and globally ‘brighten’ or ‘darken’ that source
with respect to the rest of the scene.
The only reason why ‘key’ and
‘shooting stop’ are important is that they are a benchmark against which to
measure differences in reading. We’re talking about one reading being a little
below and one being above as a way of talking about the difference between two readings. Face -1 and background +2 or
face at key and background +3? The choice between those two is not as important
as the decision that the difference
between the two is 3 stops.
This concept also applies to
colour temperature – it’s not too hard to warm up and cool down the overall
shot slightly in post – but it’s nigh on impossible to change the warmth or
coolness of a specific source relative to another. The difference in colour
temperature between two sources working in one shot is much more important than
where we set the white balance.
So what I’m really asking
myself when I light, once I’ve decided what something should look like, is:
what is the brightness relationship between the different sources playing in
this scene? What is the colour relationship between them? And once that’s clear
in my head, where to set the white balance, and where to set the shooting stop,
is mostly a matter of what to show everyone in the edit and in dailies. The key
decision is about relationships, contrast, differences.
I’m not in Burgundy anymore.
It’s taken me so long to write this that I’m in a café in Bristol, and yet we’ve
only dealt with the tip of the iceberg that is the physicality of light in
space. It’s the beginning of a mindset that leads us to think with the camera
“behind us”. We’re not thinking about what’s on the monitor, we’re thinking in
terms of footcandles, keys, reflectivity, footlamberts. We no longer have to
light from behind the camera and the monitor, but we can use those tools to our
advantage when we judge that it’s useful. We can light with our eyes and our understanding
of how the light is playing in the scene, and then walk back to the viewfinder
confident.
Burgundy and Bristol, May 2015
*The footcandle level is more formally known as the illuminance,
and is measured in footcandles. The footlambert level is formally known as the
luminance, and is measured in footlamberts.
**Read The Negative
and The Print by Ansel Adams.
***They give
you a T stop once you tell them what ISO and frame rate you’re shooting at, but
what they’re actually measuring is footcandles, and the ones specialised for cinematography
can read out directly in footcandles.


